My openmetrics package is now available on
CRAN. The package makes it
possible to add predefined and custom “metrics” to any R web application and
expose them on a /metrics endpoint, where they can be consumed by
Prometheus.
Prometheus itself is a hugely popular, open-source monitoring and metrics
aggregation tool that is widely used in the Kubernetes ecosystem, usually
alongside Grafana for visualisation.
To illustrate, the following is a real Grafana dashboard built from the default
metrics exposed by the package for Plumber APIs:
Adding these to an existing Plumber API is extremely simple:
openmetrics is designed to be “batteries included” and offer good built-in
metrics for existing applications, but it is also possible (and encouraged!) to
add custom metrics tailored to your needs, and to expose them to Prometheus even
if you are not using Plumber or Shiny.
More detailed usage information is available in the package’s
README.
The Plumber package is a popular way to make R
models or other code accessible to others with an HTTP API. It’s easy to get
started using Plumber, but it’s not always clear what to do after you have a
basic API up and running.
This post shares three simple endpoints I’ve used on dozens of Plumber APIs to
make them easier to debug and deploy in development and production environments:
/_ping, /_version, and /_sessioninfo.
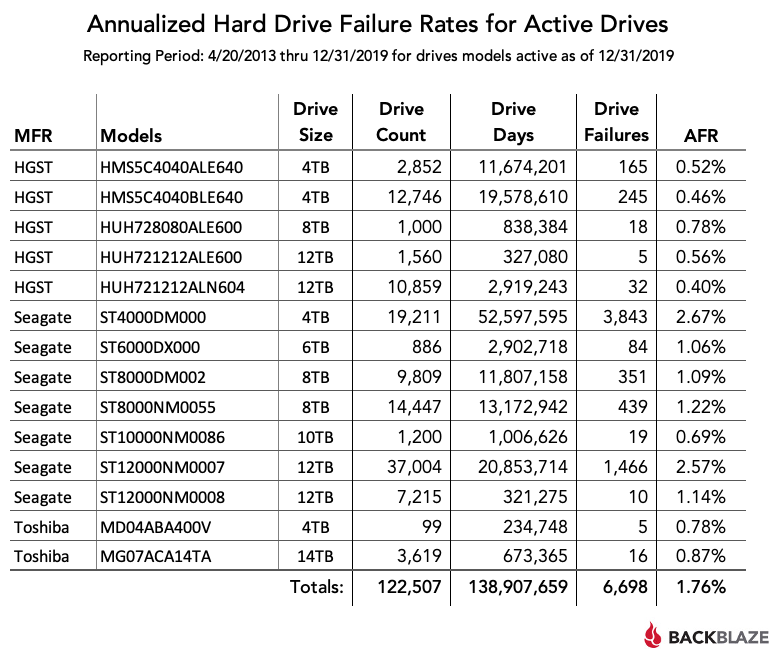
Each quarter the backup service BackBlaze publishes data on the failure rate of
its hundreds of thousands of hard drives, most recently on February
11th. Since the
failure rate of different models can vary widely, these posts sometimes make a
splash in the tech community. They’re also notable as the only large public
dataset on drive failures:
One of the things that strikes me about the presentation above is that BackBlaze
uses simple averages to compute the “Annualized Failure Rate” (AFR), despite the
fact that the actual count data vary by orders of magnitude, down to a single
digit. This might lead us to question the accuracy for smaller samples; in fact,
the authors are sensitive to this possibility and suppress data from drives with
less than 5,000 days of operation in Q4 2019 (although they are detailed in the
text of the article and available in their public datasets).
This looks like a perfect use case for a Bayesian approach: we want to combine a
prior expectation of the failure rate (which might be close to the historical
average across all drives) with observed failure events to produce a more
accurate estimate for each model.
A video of my presentation from EmacsConf 2019 is
now available. You can check out the recording below or see the slides
here.
Browser-based applications can sometimes punish even new machines. In 2015, due
to limited hardware, I was no longer able to use the popular video streaming
site Twitch.tv to follow eSports. I investigated some alternatives at the time,
but they lacked discovery and curation features, and so I decided to write a
full-fledged Twitch client in my favourite text editor, Emacs. Years later, I
still use this little bit of Emacs Lisp almost every day.
The talk discusses how I was able to use the richness of the built-in Emacs
features and some community packages to build this client, as well as the
various bumps along the way.
If you’ve used the Plumber package to make R models
or other code accessible to others via an API, sooner or later you will need to
decide how to handle and report errors.
By default, Plumber will catch R-level errors (like calls to stop()) and
report them to users of your API as a JSON-encoded error message with HTTP
status code 500 – also known as Internal Server Error. This might look
something like the following from the command line:
There are two problems with this approach: first, it gives you almost zero
control over how errors are reported to real users, and second, it’s badly
behaved at the protocol level – HTTP status codes provide for much more
granular and semantically meaningful error reporting.
In my view, the key to overcoming these problems is treating errors as more than
simply a message and adding additional context when they are emitted. This is
sometimes called structured error handling, and although it has not been
used much historically in R, this may be changing.
As you’ll see, we can take advantage of R’s powerful condition system to
implement rich error handling and reporting for Plumber APIs with relative ease.