Author’s note: this is a lightly modified version of the talk I gave at the GTA R User’s Group in May of this year. You can find the original slides here. Unfortunately, the talk was not recorded.
As I have noted before, most resources for R package authors are pitched at those writing open-source packages — usually hosted on GitHub, and with the goal of ending up on CRAN.
These are valuable resources, and reflect the healthy free and open-source (FOSS) R package ecosystem. But it is not the whole story. Many R users, especially those working as data scientists in industry, can and should be writing packages for internal use within their company or organisation.
Yet there is comparatively little out there about how to actually put together high-quality packages in these environments.
This post is my attempt to address that gap.
At work we have more than 50 internal R packages, and I have been heavily involved in building up the culture and tooling we use to make managing those packages possible over the last two years.
I’ll focus on three major themes: code, tooling, and culture.
Why Should You Write R Packages for Internal Use?
At the outset, it is worth repeating that R packages are the best way to share R code and keep it well-maintained and reliable. This matters even more inside an organisation or when you are part of a team.
The most salient reason why this is the case is that common tools to make your R
code robust, portable, and well-documented are only available
for use with packages: R CMD check, testthat, and roxygen are all good
examples.
I would push this further than most, and suggest you put as much R code as you can get away with inside packages. For instance, we put all production models in R packages, much of our ETL, and a good portion of our Shiny apps – which has recently become a lot easier due to the excellent golem package.
The Code: What Can Internal Packages Contain?
It is a oft-repeated observation that when you find yourself copy/pasting the same function or snippet of R code between projects, it might be time to push that code into a package.
Inside a business or organisation, functions that I’ve seen generally fall into a small number of categories:
-
Tools for making data easy to access and use correctly. For example, accessing the right database with the right credentials.
-
Plot themes and other internal conventions ported to R, such as presentation templates.
-
Business logic, which are conversions and routines that are highly specific to your organisation or industry; and
-
Encoding process in code – e.g. automation of team or company-specific tasks.
As an illustration, all of the following are real functions from our internal packages:
# Accessing data.
pull_data(...)
mongo_collection(...)
# Plot themes and templates.
theme_pinnacle(...)
pinnacle_presentation(...)
# Business logic.
vig_cents_to_percent(...)
get_clp_est(..)
# Encoding process.
send_to_slack(...)
rnd_release(...)
There could be other good candidates. As I mentioned, we put models, Shiny applications, and ETL into packages when possible, some of which turns into reusable code.
The Tooling: Limitations and Opportunities
Unlike the CRAN/FOSS world, in an organisation you’ll have limited power to choose the tools your organisation (already) uses for collaboration and development. And, unless you’ve got a compelling reason, you should adopt your organisation’s existing tools.
For example, my organisation uses TeamCity for continuous integration, which does not support R out of the box. In order to get access to shared CI resources, we had to make this possible (which involved using Docker and some custom scripts).
The upside of this is that we could then hook into integrations used by the rest of the organisation. For instance, Slack alerts for R packages that pass or fail their CI tests:

Because everyone is required to use the same tools, you can sometimes turn this to your advantage and leverage a shared tool for opportunities you might not otherwise have.
For example, since everyone is required to be in the same Slack channel or read their corporate email, you can ensure that everyone is notified of important R package releases – ie. this is our Slack bot that posts R package releases:
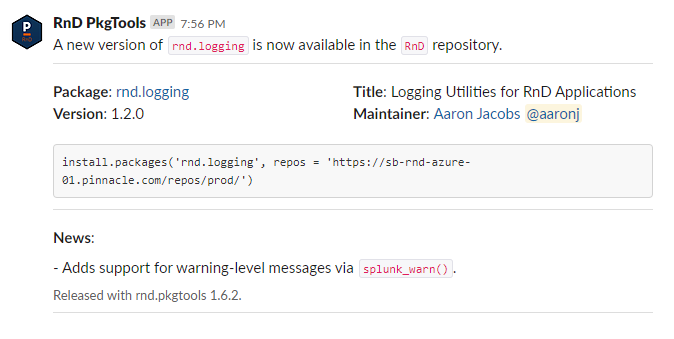
This kind of broadcast is genuinely impossible for CRAN packages, because there is simply no medium by which to contact all R users. FOSS communities are and always will be more decentralised and heterogeneous.
Moreover, tools can create data (e.g. releases, downloads, commit activity, email messages, Slack messages) that can be analysed to help you measure and understand bottlenecks or problems with your internal processes, since you know they represent the whole picture. I’ve used these data to decide what would help my team by more productive on several occasions.
The Culture: Authorship vs. Maintainership
Ultimately, I think the biggest difference between FOSS and proprietary R packages is a cultural one.
Most CRAN packages are written by someone trying to scratch an itch. Maybe that’s a new statistical method or data transformation, or a new approach to a older ones; maybe it’s a new data format that you need access to from R; or maybe it’s just a bundle of cool stuff you’ve done that you want to make more widely accessible.
There are some consequences of this model. Even if the package is released to CRAN, the expectation is that the original author will (1) design the APIs; (2) write the code; and (3) maintain the package. The author will make all the major decisions about where the package goes and be the authority on why code works the way it does.
The author unconsciously acts as though they will maintain the code forever (or more likely: until the package is abandoned).
I call this an Authorship paradigm.
These packages have a bus factor of exactly 1 – that is, if the author gets hit by a bus, that’s probably the end of the project. It is not an usual state of affairs for FOSS software, by any means.
Things are dramatically different for proprietary code:
-
You likely inherited a codebase you did not design, and it is your job to maintain it, to understand it, and to be the person to ask about bugs and new features.
-
You will not maintain new code you have designed/written forever. At some point it will likely be someone else’s job.
I call this a Maintainership paradigm.
What does this imply about writing R packages? Well, you should write the kind of R code you’d like to maintain.
What Kind of R Package Would You Like to Maintain?
This is not a trick question. You want to see
-
Clear R source code with helpful comments.
-
Good documentation, with clear explanations and examples, and an overview of the main package features in a
READMEfile. -
A test suite, both as additional examples and also to help prevent you from introducing regressions.
-
A documented history: an up-to-date
NEWSfile and clear git commit history.
In other words, pretty much all of the usual advice. The difference is that you are primarily motivated by collaboration with current and future coworkers.
In sum, I think that there is quite a lot of overlap between “best practice” package development in FOSS and proprietary environments. The main differences arise from the motivations of package authors, the tools and ecosystems they might operate in, and the nature of the code they might write.